|
Ricerca
in banca dati per parole chiave
Cerchiamo di imparare l'uso delle banche dati da un esempio pratico.
Cercheremo quindi di selezionare e studiare i geni e le proteine
corrispondenti al sesto peptide pesante della miosina di uomo. Essa
è un complesso che interviene a livello cardiaco per la contrazione
muscolare.
ENTREZ-NCBI
- Raggiungiamo il sito www.ncbi.nlm.nih.gov
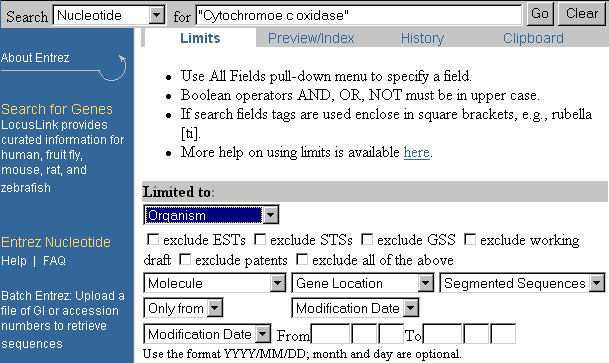
- Seleziona "Nucleotide" nella casella Search (vedi
immagine)
- E prova a richiedere la sequenza nucleotidica desiderata attraverso
l’uso della chiave:
“heavy myosin”
Nota come tra virgolette indica alla ricerca di essere effettuata
per l'intera sequenza di parole, e con quell'ordine.

- Provando ad inserire alcuni errori (es:”heavy miosin”),
si osserva come i risultati cambiano. Questo è dovuto ad
errori di battitura o nomenclatura durante l'inserimento della
entry, riferita a quella sequenza.
- Proviamo adesso a restringere la selezione richiedendo solo
le sequenze nucleotidiche relativa al sesto polipeptide.
- "myosin" AND "polypeptide 6"
- "myosin" AND "polypeptide VI"
Come si vede si ottengono risultati diversi, nonostante le nomenclature
siano differenti.
- Un altra congiunzione usata è OR, attraverso la quale
si includono i due termini di ricerca:
"myosin" AND ("polypeptide 6" OR "polypeptide
VI")
- E' possibile anche includere la sigla "MYH6"che identifica
la subunità da noi cercata.
- Ma possiamo anche fare più ricerche ed incrociarle tra
loro, rendendo così più facile il processo di selezione:
- Proviamo a far selezinare tutte le sequenze di uomo. Digitando
“homo sapiens” e selezionando l’opzione Organism
nel campo Limits, ed infine avviando la ricerca, avremo 'in memoria'
la selezione.
- Poichè vogliamo incrociarle con l'ultima ricerca fatta
(quella che identificava una generica cox4), andiamo nella finestra
"History", dove troveremo le ricerche fatte finora,
e le relative entry trovate. Per incorciare le ricerche, basterà
far cercare ad esempio "#8 AND#10", perchè si
incrocino le ricerche 8 e 10, fornendo i risultati comuni alle
due ricerche.
In questo modo è possibile fare una serie di selezioni,
rendendo molto efficace il processo di ricerca, e affinamento
dei risultati.
- Così se osservassimo degli pseudogeni nei nostri risultati
ptremmo facilmente eliminarli, facendo prima una ricerca per "pseudogene",
e poi indicare "#8 AND #10 NOT #11"
- Eliminando anche le sequenze EST (siamo interessati all'intera
sequenza), possiamo poi selezionare la sequenza che interessa
(es: AF017115) e visualizzare le informazioni contenute nella
entry nei diversi formati.
SRS-EMBL
- SRS è un altra banca dati, europea, mentre la precedente
americana. Poichè abbiamo modalità diverse, rifacciamo
la stessa operazione anche con questo sito. http://srs.ebi.ac.uk
- Clicchiamo sulla sezione "Library Page" per selezionare
la banca dati su cui fare la ricerca. Questa permette di fare
già una selezione, in funzione se quello che vogliamo cercare
sono particolari sequenze (ad esempio di interesse immunologico),
o meno.
Selezioniamo la banca dati EMBL e clicchiamo a sinistra, su "Standard
query form"
- Ora inseriamo la chiave di ricerca "cytochrome c oxidase"
nel campo AllText
e clicchiamo su Search
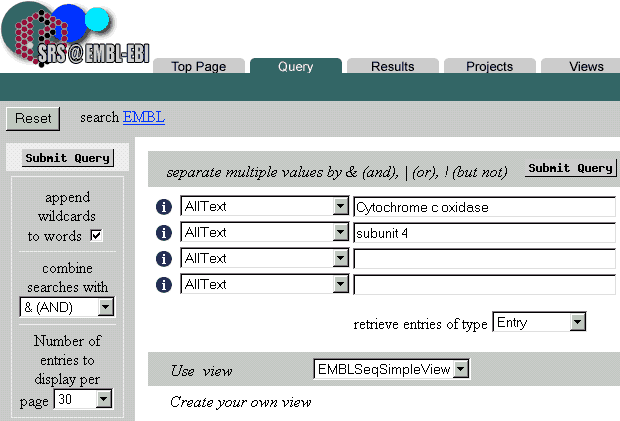
- Ora proviamo a combinare più chiavi.
Andando sulla sezione "QueryForm" la banca dati rimane
quella selezionata precedentemente. Proviamo a indicare nel primo
campo "myosin" nel secondo "MYH6".
Nota come sulla sinistra, è possibile indicare se il contenuto
dei due campi appena digitati devono essere cercati insieme (AND),
o meno (NOT, BUT NOT).
Inoltre è possibile cercare il contenuto del campo non
solo in "AllText", maa nche in una specifica parte dell'entry
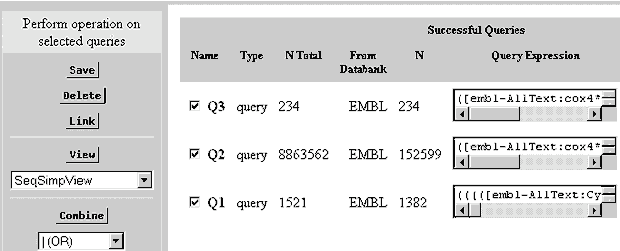
- Similmente al sito dell'NCBI possiamo combinare i risultati
di diverse ricerche.
Selezioniamo la sezione"Results"
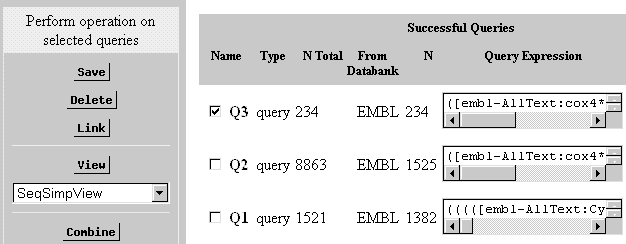
- Selezioniamo le queriesche ci interessano, ed applichiamo l'operatore
logico (AND, OR,etc) ed infine "Combine", combiniamo..
- Tra tutte le sequenze trovate dobbiamo selezionare solo quelle
relative alla specie “Homo sapiens”
- Torna nell’area Query, seleziona Organism nel menù
a tendina e immetti il nome "Homo sapiens"
- Torna in Result e combina l’ultima query con le queries
precedenti (Q5 e Q6 otterremo Q7) utilizzando l’operatore
AND
- Per completare la selezione bisogna escludere gli pseudogeni
- Torna nell’area query digita pseudogene nella finestra
All text e clicca submit (otterremo la query Q8)
- Nell’area Result combina la penultima query con la query
“pseudogeni” utilizzando l’operatore BUTNOT,
in questo caso scriviamo la query nella finestra expression:
Q7!Q8 (otterremo la query Q9)
- Possiamo anche escludere tutte le sequenze riferite al
genoma mitocondriale
- Dall’area Query seleziona Organelle nel menù e
digita mitochondrion nella corrispettiva finestra (Query
Q10)
- In Result combina Q9!Q10
Come si può subito notare, esistono differenze sostanziali
nell’uso dei due sistemi di Retrieval, Entrez e SRS.
Il numero di sequenze che otteniamo attraverso i due sistemi è
diverso a causa di un diverso aggiornamento delle banche dati
utilizzate dai due sistemi di interrogazione.
- Il sistema SRS consente di estrarre sequenze di altri database
che siano (o meno) correlate con le entries selezionate.
- Nell’ area Results, seleziona una query e l’opzione
Link
- Proviamo ad estrarre le sequenze proteiche, contenute nella
banca dati SWISSPROT, associate alle sequenze nucleotidiche da
noi selezionate.
- Seleziona la Banca dati SWISSPROT e clicca su Submit Link.
- Tra tutte le entries possiamo selezionarne una (es: NP_002462)
e vedere a che corrisponde.
ESERCIZI PROPOSTI
- Con SRS prova ad estrarre tutte le sequenze umane del gene che
codifica per la quarta subunità della citrocromo c ossidasi,
sequenziate da mRNA.
- Con Entrez estrai le sequenze per lo stesso gene ma nel topo
|


