| Autore |
Discussione |
|
|
Weanz
Nuovo Arrivato

Prov.: Padova

11 Messaggi |
 Inserito il - 25 settembre 2007 : 16:35:30 Inserito il - 25 settembre 2007 : 16:35:30




|
L'ipotesi H0 � che L'utente sottoposto al test non riesca a ditinguere i suoni quindi tutte le medie per i diversi aggettivi siano le stesse.
Questo per� ho visto gia che non accade, Ho una F molto alta, quindi i vari aggettivi vengono riconosciuti come distinti o almeno uno di quelli risulta distinto dagli altri.
Per� so dalla letteratura che aggettivi come calmo e triste verranno sicuramente confusi. Come valutare questo?
Inoltre posso io mettere nelle colonne invece che gli aggettivi i diversi tipi di parametri?
Ti faccio un esempio di tipo medico che ricalca il mio.
Immagina che stai studiando una certa malattia, stai testando il successo di due farmaci(brani-T e aggettivi-T), fai tre prelievi di sangue uno dietro all'altro in 9 condizioni diverse (al mattino, a digiuno da tre giorni, dopo mangiato, dopo che il paziente ha fatto sport, quando dorme, mentre � al bagno ecc..).Sono crudele lo so...
Inoltre gli misuri anche la pressione e la temperatura del soggetto inoltre per ogni prelievo ricavi pi� parametri sull'esame del sangue(i miei 8 parametri sonori).
1) vorresti capire quale � quel valore del sangue che ti permette meglio di valutare la risposta della malattia ai due farmaci.
2)Poi vorrei capire l'effetto delle condizioni sulla malattia.
3)Infine l'effetto dei due farmaci sulla malattia.
Io ho tutti i valori dei prelievi.
Che dici? meglio? In effetti � l'esperimento progettato male. Quindi l'analisi dei dati risulta un macello.
P.S. si probabilmente con sto metodo i pazienti sarebbero tutti morti, ma fa finta che � gente tosta...  |
 |
|
|
TMax
Utente Junior


Prov.: BG
Citt�: Capriate
270 Messaggi |
 Inserito il - 26 settembre 2007 : 10:08:03 Inserito il - 26 settembre 2007 : 10:08:03
|
ok l'esempio 'medico' che hai fatto � quello che di solito 'purtroppo'
si trova in letteratura scientifica...
dico putroppo perch� non si fa cosi, non si possono misurare tante variabili e poi andare a cercare quelle 'statisticamente significative', questa operazione si chiama in termine tecnico : fishing data, o dredging data, in italiano: spedizioni di pesca o dragaggio dei dati...
� si tratta dell'inappropriata , talvolta deliberata, ricerca di significativit� statistiche in grandi quantit� di dati.
� possibile testare solo un ipotesi
ogni volta che fai un test (confronti multipli o testi pi� ipotesi per variabili differenti) ottieni un inflazione dell'errore di primo tipo, cio� aumenta esponenzailmente la probabilit� di dire che ci sono delle differenze quando in realt� non ci sono...
tornando al tuo lavoro, dici:
L'ipotesi H0 � che L'utente sottoposto al test non riesca a ditinguere i suoni quindi tutte le medie per i diversi aggettivi siano le stesse.
chiariscimi due cose:
1. questa � l'ipotesi sperimentale o l'ipotesi statistica .. sono due cose diverse... la prima si riferisce a quella che lo sperimentatore plausibilmente aspetta di vedere dai risultati dello studio, ad esempio se uno mette a punto un nuovo farmaco, l'ipotesi sperimentale � che il farmaco nuovo � pi� efficacie del farmaco vecchio...
l'ipotesi statistica sar� il farmaco nuovo � efficacie come quello vecchio..
ti ricordo che � possibile solo falsificare l'ipotesi nulla!
2. di quali medie parli quando dici che sono tutte uguali per i diversi aggettivi ( ?? medeie dei millisecondi che ci mettono a raggiungere un certo punto??, medie delle coordinate?? ???)
TMax
|
|
|
|
Weanz
Nuovo Arrivato
Prov.: Padova
11 Messaggi |
Inserito il - 26 settembre 2007 : 12:50:32
|
Citazione:
Messaggio inserito da TMax
chiariscimi due cose:
1. questa � l'ipotesi sperimentale o l'ipotesi statistica .. sono due cose diverse... la prima si riferisce a quella che lo sperimentatore plausibilmente aspetta di vedere dai risultati dello studio, ad esempio se uno mette a punto un nuovo farmaco, l'ipotesi sperimentale � che il farmaco nuovo � pi� efficacie del farmaco vecchio...
l'ipotesi statistica sar� il farmaco nuovo � efficacie come quello vecchio..
ti ricordo che � possibile solo falsificare l'ipotesi nulla!
2. di quali medie parli quando dici che sono tutte uguali per i diversi aggettivi ( ?? medeie dei millisecondi che ci mettono a raggiungere un certo punto??, medie delle coordinate?? ???)
Allora concordo nella tua osservazione del troppi dati, per� forse nel mio caso non � possibile fare altrimenti. Cerco di esser chiaro.
Se tu devi studiare l'effetto di una canzone nel tuo modo di lavorare non � lo stesso far sentire questa canzone a 5 persone oppure far sentire a queste persone una volta solo la batteria, una volta solo la chitarra una volta solo la voce in tracce separate. Non pu� avere lo stesso effetto. Cosi devo fare anche io quindi non posso separare (anche se si poteva) i vari parametri sonori, perch� � la loro fusione che crea l'effetto che devo studiare.
Per il resto si entra nel profondo della tesi, per cui ci sono un sacco di fenomeni psicopercettivi che rompono le scatole..(per esempio la gente si ammassava lungo il bordo del cerchio in cui poteva muoversi...).
Riguardo alle domande specifiche, non son sicurissimo di rispondere correttamente ma direi che � l'ipotesi statistica. Io mi aspetto che riconoscano, ma statisticamente, se ho sbagliato tutto, metteranno a caso, quindi non ci saranno differenze importanti tra le medie dei vari parametri, giusto?
Se invece ho fatto un buon motore audio mi aspetto che siano confermati i risultati precedenti e quindi che le medie dei parametri siano diverse da aggettivo ad aggettivo e cio� che i soggetti distinguano sul piano punti diversi, per diversi aggettivi.
ti allego un file che chiarisce almeno graficamente come sono disposti gli aggettivi in base ad un altro esperimento di classificazione, in cui � stata usata la PCA le righe gialle sono i miei paramtri sonori che variano dal massimo al minimo lungo quelle direzioni.
Immagine:
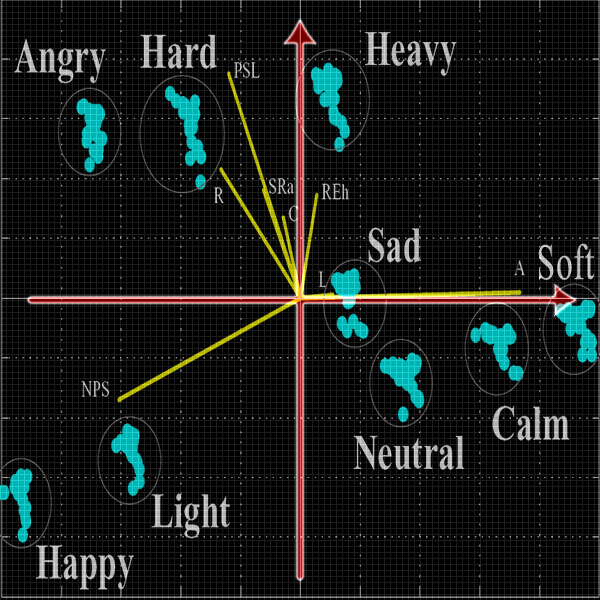
95,74 KB
Come vedi gli aggettivi si possono distinguere in tre cluster (anche in letteratura):
Primo: angry, heavy, hard
Secondo: happy light
Terzo: calm soft sad neutral
Quindi potrei fare un anova all'interno dei cluster visto che i soggetti probabilmente avranno confuso con pi� facilit� gli aggettivi all'interno dei singoli cluster.
|
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 08 ottobre 2007 : 15:41:00
|
ciao scusa il ritardo ,
inizio a pensare che non sia un problema di analisi della varainza , ma piuttosto di classificazione,
se ho capito bene l'interesse � nella capacit� di classificare correttamente un certo carattere musicale, quindi io stimerei la probabilit� che un soggetto ha di classificare correttamente un carattere verbale o un brano musicale, e poi quali sono i fattori in grado di modificare questa probabilit�.
La stima della prob la farei usando un modello di regressione logistica.
per� tutto ci� � vero se ho capito il disegno e il fine dello studio...
riesci a predisporre i tuoi dati, aggiungendo per ogni soggetto una colonna, con una variabile dicotomica (corretto/non corretto) che indica se il soggetto ha classificato correttamente il suono/brano?
TMax |
|
|
|
Weanz
Nuovo Arrivato
Prov.: Padova
11 Messaggi |
Inserito il - 08 ottobre 2007 : 16:07:47
|
Si volendo si potrebbe, ma i dottorandi che mi seguono mi han fatto notare che non sarebbe molto corretto visto che cmq i risultati mostrano che i soggetti hanno trovato i caratteri espressivi in posizioni leggermente diverse dal modello di partenza. Quindi se io considero il modello di partenza, trovo che han tutti sbagliato. Invece non � cos�, perch� magari i valori che ho scelto per i vari parametri sonori sono poco adatti e hanno distorto il piano iniziale (di fisso avevo solo le direzioni in cui variano).
Cmq per il momento ho fatto una manova con x e y. Poi ho fatto una classificatore alla minima distanza.
I dati ve li posto volentieri, ma sono numerici in file di testo.
Appena ho il capitolo fatto vi posto quello che ho combinato.. :-P |
|
|
|
Weanz
Nuovo Arrivato
Prov.: Padova
11 Messaggi |
Inserito il - 23 ottobre 2007 : 18:27:55
|
Allora missione compiuta, cerco di spiegare cosa ho fatto:
Per primo cosa visto che una coordinata da sola nel mio caso non ha significato per il mio studio, ho optato per un test MANOVA.
Il test MANOVA utilizza pi� variabili dipendenti e nel caso di MANOVA ad una via, i risultati vanno letti esattamente come fosse un ANOVA solo che invece di considerare le medie di un parametro se ne considera la centroide (quindi l'unione ordinata delle medie di pi� parametri correlati tra loro).
Usando Matlab MANOVA restituisce due risultati: la dimensione calcolata dello spazio dei parametri "d" e la relativa probabilit� che quella sia la dimensione, la decisione sulla dimensione viene presa in base al parametro di significativit� alpha uguale a 0.05 o altro che si voglia imporre.
Es. immaginiamo di avere due gruppi di omini su una piazza. Se questi sono tutti al centro della piazza, la dimensione della MANOVA stimata sar� zero. Altrimenti se i due gruppi sono separati il test MANOVA restituir� una dimensione uguale a 1 (una retta nello spazio). Ci� significa che i due gruppi non appartengono alla medesima popolazione.
Ho fatto una MANOVA con variabili dipendenti X e Y, ho trovato una dimensione uguale a 2. Cio� il massimo possibile.
Ho fatto un secondo test MANOVA, considerando come variabili dipendenti, i sei parametri sonori, ho trovato una dimensione accettabile uguale a 4.
Poi ho eseguito un test MANOVA per tutte le possibili combinazioni tra gli aggettivi cos� ho valutato quali coppie di aggettivi venivano confuse e quali no.
Alla base � necessario essere sicuri che non vi siano outliers, altrimenti il test MANOVA come L'ANOVA diventa "ottimista", e risulta pi� separazione di quanto invece nn ce ne sia in realt�.
Sicuramente nel mio caso un ANOVA non ha molto significato appunto perch� considerare solo le x o le y potrebbe indicare come confusi aggettivi che invece non lo sono.
Grazie a tutti! |
|
|
|
Cristina80
Nuovo Arrivato
4 Messaggi |
Inserito il - 10 febbraio 2009 : 11:27:36
|
Ciao a tutti anch'io sono nuovissima di questo sito! Ho bisogno del vostro aiuto :-)
Sto analizzando dei pazienti che sono stati appena operati ed ho delle variabili che sono state misurate in tempi diversi. Ad esempio la pressione misurata subito prima dell� intervento, dopo l�intervento, poi a 6 mesi, 12 mesi, 18 mesi e 24 mesi. Vorrei capire se nel tempo c�� una differenza significativa dei valori della pressione. Dovrei usare l�Anova a misure ripetute? S'� corretto questo test qualcuno � cos� gentile e puoi spiegarmi come utilizzare excel o spss per effettuare l�anova a misure ripetute?
Grazie molte in anticipo
|
|
|
|
domi84
Moderatore


Citt�: Glasgow
1724 Messaggi |
|
|
Itachi Uchiha
Nuovo Arrivato
2 Messaggi |
Inserito il - 17 febbraio 2009 : 21:21:38
|
Ciao a tutti sono nuovo !Sono capitato su questo forum dato che ho dei problemi con Multifactor anova. !Sono capitato su questo forum dato che ho dei problemi con Multifactor anova.
Sto usando Static Graphics e sto facendo un analisi con Multifactor Anova con :una variabile dipendente e 5 indipendenti. Devo studiare l'impatto(controllare se hanno i P-value<aplha) delle 5 variabili indipendenti su quella dipendete.Uso il Multifactor Anova imposto la Dependent variable e le altre 5 le imposto come Factors.Faccio partire il tutto ma mi da errore dicendomi che c'� dipendenza lineare tra 3(delle 5) variabili dipendenti!I dati sono corretti perche li ha forniti il Prof!Come posso risolve questo problema?Sbaglio in qualcosa?Un altra domanda,forse banale..una volta che trovo i fattori che hanno impatto(P-value<alpha)che cosa devo dire su di essi?Che al loro aumentare o diminuire succede qualcosa..?
Grazie in anticipo! |
|
|
|
mds65
Nuovo Arrivato

1 Messaggi |
Inserito il - 08 ottobre 2009 : 12:32:54
|
Salve a tutti gli amici del forum; sono nuovo e vorrei porvi delle domande su come effetuare l'analisi statistica su dei dati che mi hanno inviato; ho 9 stazioni di campionamento in mare: A, B, C, D, E, F, G, H, I; sono stati effettuati dei campionamenti in ognina delle 9 stazioni, misurando in percentuale alcuni valori, quale Curvilinear Velocity % (VCL), Straight Line Velocity % (VSL), Average Path Velocity % (VAP), Spermatozoi pi� veloci % (rapidi), Fecondazioni % (plutei), Saggio di inibizione % (mtox) al tempo t=0 e la tempo t= 5gg. Se voglio confrontare tutte le variabili al tempo t0 con tutte la variabili al tempo t5 per tutte le stazioni di campionamento che tipo di analisi devo fare? una MANOVA? Io uso come software Statistica 8.0 della StatSoft.
Vi ringrazio in anticipo della Vs. disponibilit�. |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 13 ottobre 2009 : 15:34:43
|
Ciao,
quello che ti accingi a fare in termini tecnici va sotto il nome di 'dragging data' o detta all'italiana ...battuta di pesca..
cio�.. in assenza di ipotesi si fanno tutti i test possibili alla ricerca delle fantomatiche significativit� statistiche...
n� pi� n� meno che lanciare una rete e sperare che venga su del buon pesce.
Questo metodo � poco raccomandabile ed � ampiamente discusso in letteratura scientifica.
Quello che ti consiglio e considerare separatamennte ogni parametro e analizzarlo con una analisi della varianza per misure ripetute (avendo a che fare con % dovrai fare prima una trasformazione dei dati tramite la funzione arcoseno), o meglio un modello lineare ad effertti misti. Poi conti tutte le analisi fatte cio� tutti i confronti fatti ..
se ad esempio per ogni parametro stimi l'effetto 'stazione di rilevamento' e poi l'effetto tempo sono 2 confronti quindi se hai 6 parametri hai un totale di 8 test.. quindi il tuo valore di p da usare per definire la significativit� statistica dei risultati sar� 0.05/8=0.00625....
tutto ci� se l'assunto di base � che non c'� nessuna relazione tra i parametri che stai studiando
in caso contrario dovresti fare una MANOVA e la cosa si complica enormemente...
putroppo ai ricercatori non insegnano a disegnare gli studi!
TMax |
|
|
|
omar83
Nuovo Arrivato
7 Messaggi |
Inserito il - 14 agosto 2012 : 16:08:43
|
Ciao a tutti!Vorrei un aiuto per uno studio che sto seguendo. Vi spiego la situazione. Ho 30 soggetti pazienti neuropsichiatrici e 20 soggetti di controllo. Per ciascun soggetto sono state effettuate delle misurazioni volumetriche di parti anatomiche del cervello (ad esempio cervelletto, amigdala, ippocampo etc...), e sono stati raccolti i rispettivi dati socio anagrafici (et�, sesso, scolarit� etc...). Lo scopo � comprendere quali volumetrie siano significativamente differenti tra soggetti di controllo e pazienti. Ho fatto ci� con dei semplici test (tipo wilcoxon, t test)confrontando di volta in volta ogni singola tipologia volumetrica tra controlli e pazienti (es. amigdala pazienti VS amigdala controlli). Ora per� vorrei effettuare un'analisi pi� accurata (dato che in letteratura ho raramente riscontrato dei confronti con dei semplici t test o simili). L'idea � che ci siano delle variabili che influiscano sulle volumetrie (ad esempio l'et� o il sesso) e inoltre che l'analisi sarebbe pi� accurata se si avesse modo di considerare nei test anche il volume cerebrale totale. Ho pensato di fare un'ANCOVA e usare la variabile che sospetto influire sulla volumetria considerata come covariata (ad esempio il volume cerebrale totale potrebbe essere una covariata), ma non vengono verificate le assunzioni per poter effettuare l'ANCOVA (regressione lineare della variabile dipendente sulla variabile indipendente significativa e significativo parallelismo tra le regressioni dei due gruppi:controlli-pazienti). Avete dei suggerimenti? In letteratura usano sempre ancova e manova ma non fanno cenno al rispetto o meno delle assunzioni.
Grazie a tutti! |
|
|
|
omar83
Nuovo Arrivato
7 Messaggi |
Inserito il - 14 agosto 2012 : 16:12:28
|
| Scusate se l'argomento esula dall'ambito di ricerca del forum ma dato che l'aiuto di cui necessito � di tipo statistico spero comunque di ricevere risposta. Grazie a tutti in ogni caso! |
|
|
|
omar83
Nuovo Arrivato
7 Messaggi |
Inserito il - 14 agosto 2012 : 16:15:43
|
| Di solito uso R, MATLAB o SPSS |
|
|
|
omar83
Nuovo Arrivato
7 Messaggi |
Inserito il - 05 settembre 2012 : 13:42:15
|
| Nessuno mi pu� dare una mano? |
|
|
|
TMax
Utente Junior
Prov.: BG
Citt�: Capriate
270 Messaggi |
Inserito il - 05 settembre 2012 : 14:37:22
|
ciao
ti conviene aprire un nuovo topic cosi resta pi� in evidenza
questo � molto vecchio e lungo e il tuo messaggio compare in 3 pagina � probabile che in pochi lo vedano...
Max |
|
|
|
Glubus
Utente Junior

156 Messaggi |
Inserito il - 05 settembre 2012 : 16:54:26
|
Convengo con Tmax: sposta il thread.
Aggiungerei anche: n� ANOVA ne' MANOVA, dato i contesto esplorativo, il numero notevole di variabili "indipendenti" ed numero modesto di osservazioni (tra l'altro: come mai ci sono pi� malati che sani? di solito si fa pi� fatica a trovare i primi, ...) ti suggerirei qualche metodica pi� "moderna" di analisi (Classification and Regression Trees, ad esempio).
Stefano
Citazione:
Messaggio inserito da TMax
ciao
ti conviene aprire un nuovo topic cosi resta pi� in evidenza
questo � molto vecchio e lungo e il tuo messaggio compare in 3 pagina � probabile che in pochi lo vedano...
Max
|
|
|
|
Discussione |
|



